Case Study
StageFlow
Open-source frontend quality platform: eight scanners, one report contract, and per-project regression memory for CI.
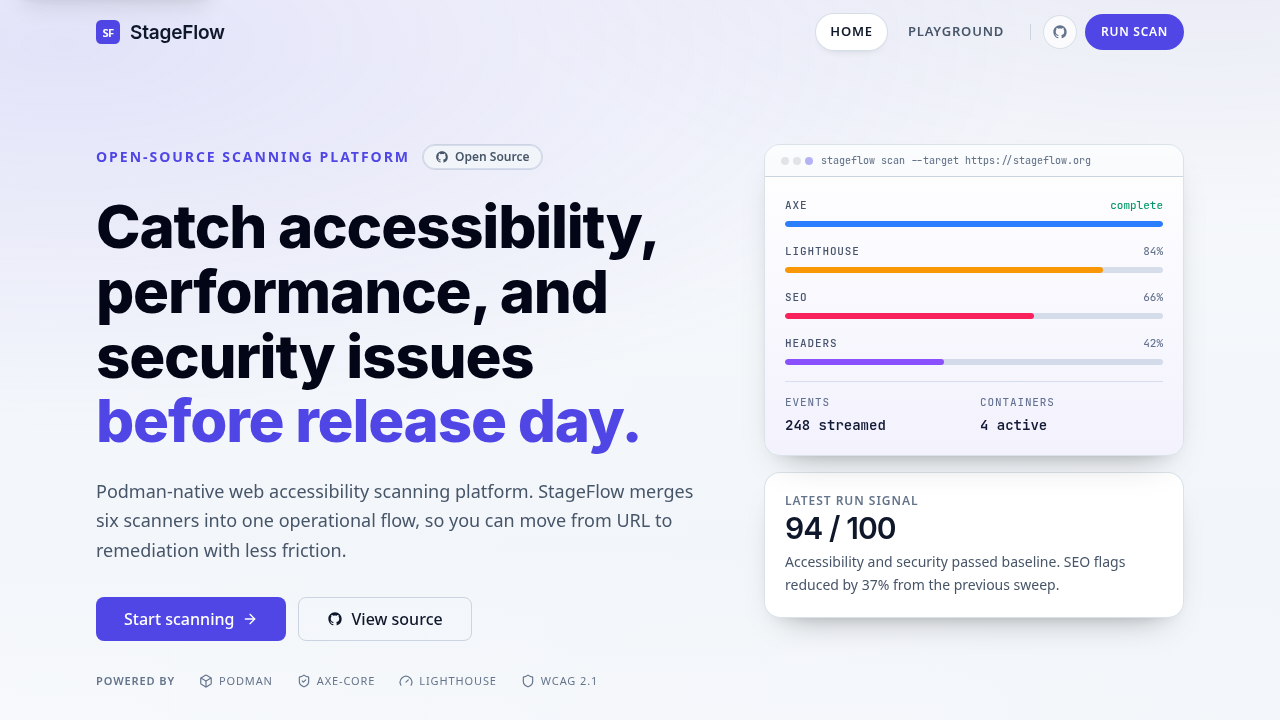
The thing that kept nagging me during the design of StageFlow was that most quality tooling gives you a wall of results with no memory. Run axe today, get 23 issues. Run it again next week after a deploy, get 24. Is that new? Did the layout change? You have no way to know unless you diff by hand.
That's the problem I wanted to solve: not just "scan a page" but "did this deploy make things worse?" The whole system is shaped around that question.
8
Built-in scanners
6
FSM states, PENDING to DONE
MIT
Open source license
The pipeline
When a scan request arrives at the Platform API, it validates the URL for SSRF — resolving the hostname and checking every returned IP against three-tier classification rules (always-block ranges, private-mode-only ranges, and public ranges). The 169.254.169.254 metadata service gets its own explicit check, not just folded into the link-local range. After validation passes, the API publishes a job.created event to NATS JetStream and immediately returns a job ID. It doesn't wait for anything.
The Orchestrator picks that event up from a durable consumer, creates a Podman pod for the job, and launches one scanner container per requested scanner. Those containers run rootless with no-new-privileges:true and per-pod CPU and memory limits. When they finish, each publishes scan.completed back to NATS with its results path in MinIO. The Orchestrator collects those events, and once all expected scanners have reported in, it downloads every results.json, merges them into a unified report, deduplicates cross-scanner findings, recalculates scores, and uploads the final artifact. The API, watching NATS for job.completed, updates the SSE stream so the browser or CLI sees the result.
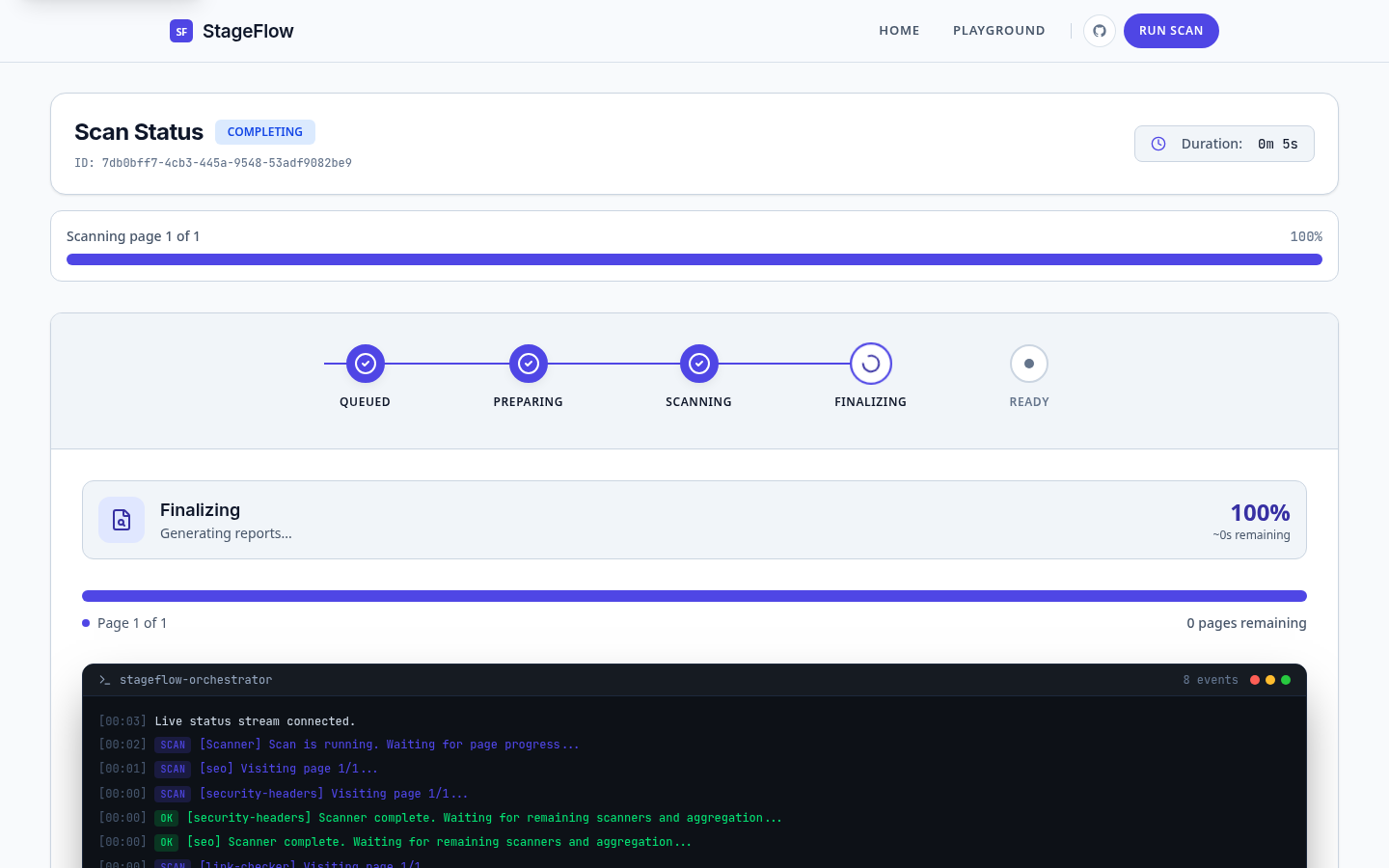
The SSE choice over WebSocket was deliberate. Job progress only flows one direction, SSE reconnects natively and survives most reverse proxies without configuration, and the SSE hub buffers recent events so a client that reconnects mid-job catches up without polling. WebSocket would have been more code for no benefit in this case.
The state machine
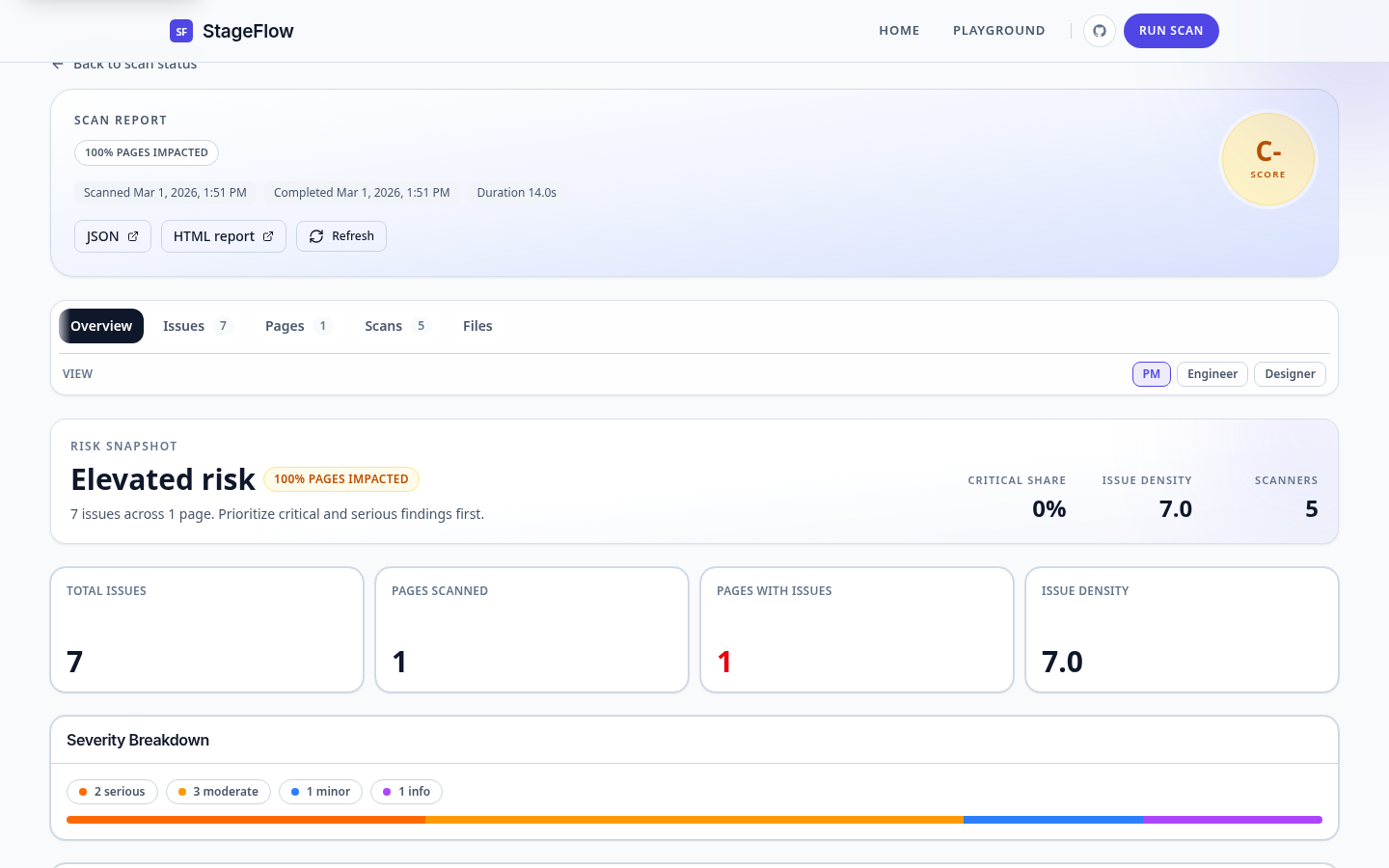
The job lifecycle is a real FSM: PENDING → EXTRACTING → READY_TO_SCAN → SCANNING → COMPLETING → DONE, with FAILED as a terminal from any state. This isn't enum values checked with if-statements scattered across handlers. The transition table lives in libs/go/domain/job/state.go, transitions are rejected at the code level if they're not in the allowed map, and database queries use a StateRankSQL() CASE expression so state regressions can't be written even if the application logic somehow allows them.
The completion policy handles partial-success cases explicitly: if some scanners succeed and some fail, the job completes with partial results rather than failing entirely. That's a separate named function, not implicit logic buried in the event handler.
Why did this matter? I've built enough async orchestration to know that implicit state encoded across multiple boolean columns or timestamps creates combinations you didn't think of. An explicit FSM surfaces every valid state up front, and "what happens when this event arrives in this state" has one clear answer.
Regression diffing
Each issue in the unified report carries a stable content hash: sha256(ruleId + context + occurrence). The same violation on the same page produces the same ID on every scan, regardless of scan order or scanner version.
The diff engine is four dozen lines in libs/go/diff/diff.go. It builds maps of id → issue for baseline and current, then does a straightforward set difference. New IDs are regressions; missing IDs are fixes. The CLI exits 1 when new issues appear, so a CI job can gate on it.
The golden test (qa/e2e/project-scan-golden.sh) exercises this end-to-end: create a project, scan a clean fixture page, promote that scan as the baseline, update the project URL to a page with an added image-alt violation, scan again, and assert the CLI exits 1 with exactly 1 new issue of severity critical and ruleId == "image-alt". If the diff engine breaks, the golden file comparison fails first. If the exit code behavior regresses, the explicit assertion catches it.
The contract layer
This is where I'd usually cut corners and let types drift. Here I didn't.
libs/contracts/ holds JSON Schema as the source of truth. Both Go types and TypeScript types are generated from those schemas. The Go side uses atombender/go-jsonschema with custom UnmarshalJSON that enforces required fields, length constraints, and enum values. The TypeScript side uses json-schema-to-typescript. If the scanner runner emits a field that the web UI's TypeScript doesn't know about, the build fails before deployment.
Beyond schema validation, the TypeScript report validator checks business-logic invariants JSON Schema can't express: that summary.totalIssues matches issues.length, that severity counts match the actual issue severities, that page IDs referenced in issues actually exist in the pages array. These aren't unit tests of the schema — they're runtime checks that fire when a report is loaded for display.
The payloads on NATS events use strict decoding (DisallowUnknownFields) to catch schema drift, while the envelopes themselves are lenient so a new producer can add fields without breaking existing consumers. I've been burned by the opposite approach enough times that the asymmetry felt obvious in hindsight.
Storage choices
PostgreSQL backs the orchestrator job state because jobs have concurrent writers (multiple scanners reporting completion at the same time), and the StateRankSQL() rank expression is a SQL constraint. SQLite backs the project metadata in the Platform API because projects are single-writer and a daemon-free database is much easier to operate in self-hosted deployments. MinIO holds all the large artifacts — screenshots, per-scanner results.json, unified reports — and clients get time-limited presigned URLs rather than direct bucket access.
Scanning behind a login
A scanner that only sees your marketing pages misses most of the app. The accessibility and SEO problems worth finding usually live behind the login, on the dashboard nobody audits because reaching it by hand is tedious. StageFlow has an authenticated mode for exactly that. You give it a login URL and a scoped account, it drives the form with Playwright, waits for the redirect that proves the login took, captures the session's storage state, and runs every scanner against the post-login surface. If a scan lands back on a login screen instead, an auth-wall detector reports it rather than letting you believe you audited a page you never reached.
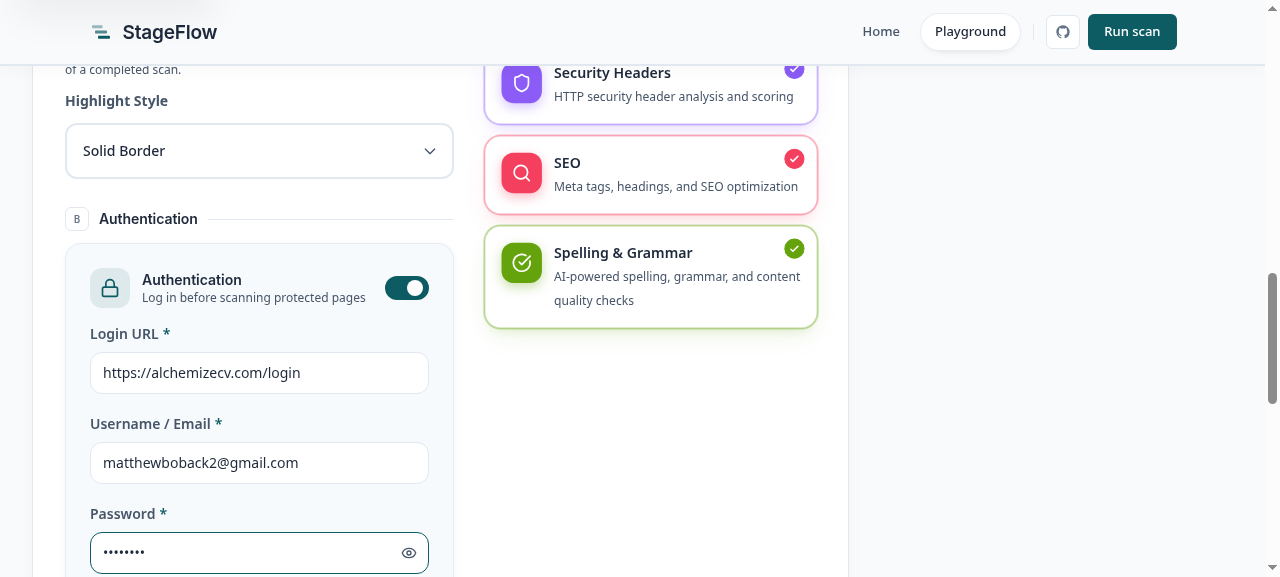
To show it working I pointed it at the dashboard of another project of mine, AlchemizeCV, using a throwaway demo account. The scanners ran against the real logged-in surface — the pipeline view, the verified-match list, the recent-activity feed — and came back with 29 findings on that single page.
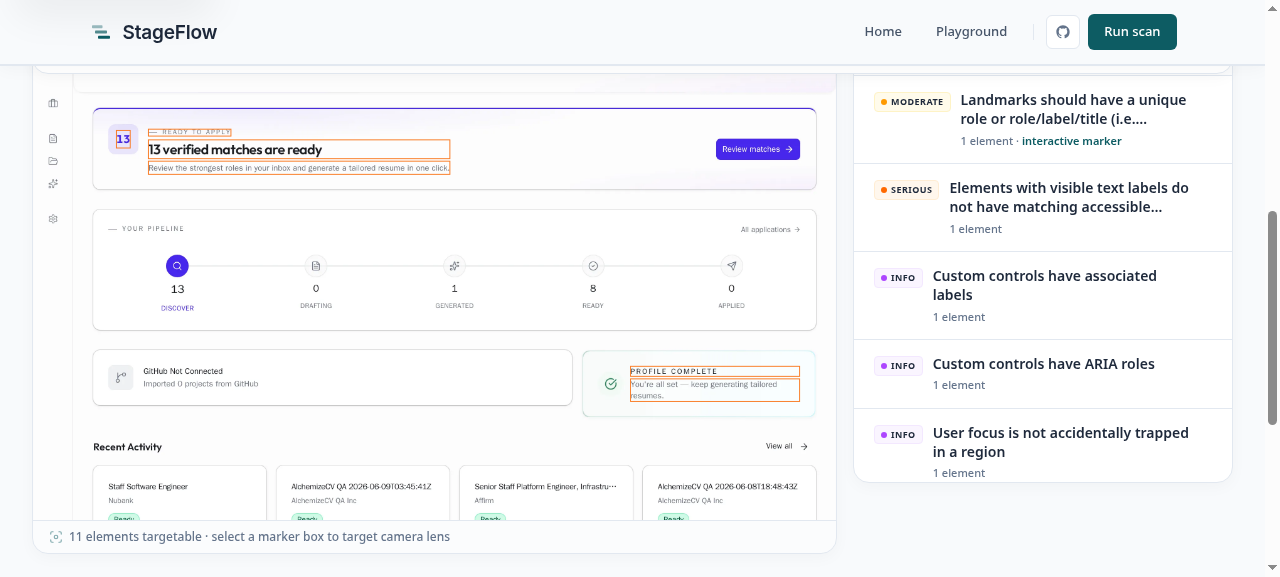
The part I'm happiest with is how the report ties a finding back to the thing on the page. Click a box, or the matching row, and the report locks its lens on that occurrence and opens the finding: the rule that fired, the CSS selector, the evidence, and a plain-language fix.
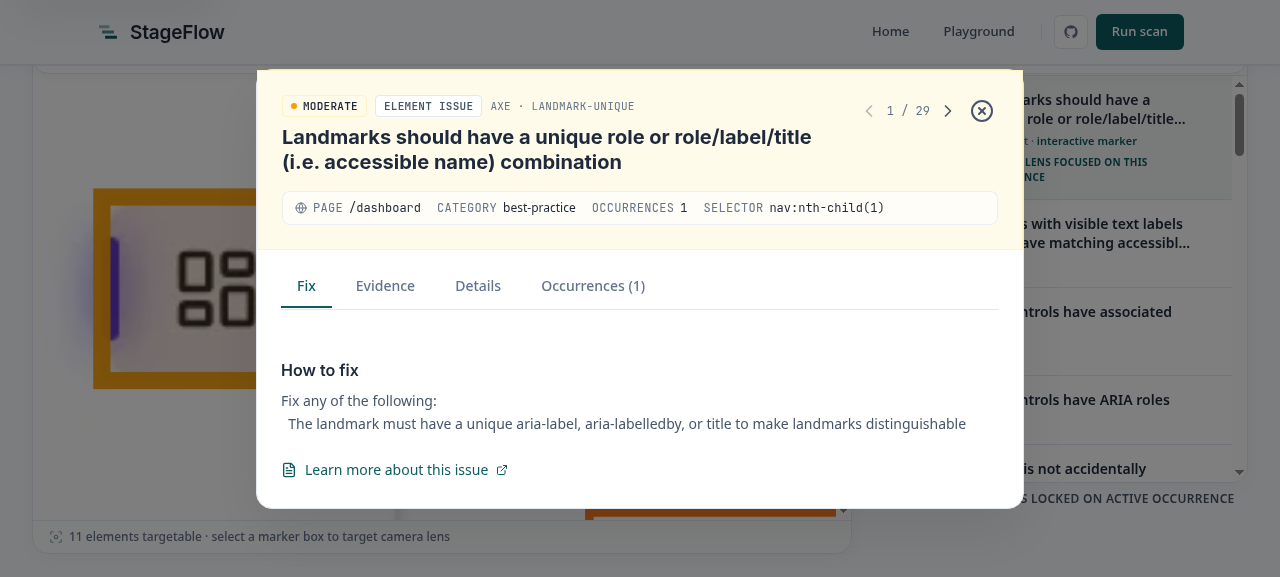
Where the security surface is
The system scans arbitrary websites using a real browser. That means two distinct concerns.
The first is SSRF at the API layer. The Platform API resolves hostnames before accepting a URL and blocks against explicit CIDR ranges plus the IPv4 metadata service endpoint. The scanner runtime applies the same policy to initial targets, redirects, and subresources. Running a public instance without this would let someone scan http://169.254.169.254/latest/meta-data/ through your infrastructure.
The second is ZIP intake. The archive extractor runs inside the job pod, not the host. It enforces entry count, per-file size, total uncompressed size, and compression ratio to catch ZIP bombs. Path traversal attempts are rejected before extraction. Even if someone crafted a malicious archive that bypassed all checks, the blast radius is the job pod, not the host filesystem.
Rootless Podman was the right choice here. No daemon, no privilege escalation, and the security posture for self-hosted deployments is meaningfully simpler.
What I'd revisit
The orchestrator's StateRankSQL() trick keeps state from regressing in the database, but it means the application still has to handle the case where a write was rejected. That conflict handling lives in a few places and the logic isn't symmetric everywhere. A proper optimistic locking strategy with version columns would be cleaner.
The authenticated scanning feature (form recipes and Playwright storage state) works, but the number of places credential values have to be explicitly not logged or not persisted is higher than I'd like. The boundary is well-tested and the invariants are documented, but it's the kind of thing where one careless log statement breaks the security model. I'd look at making the credential types structurally non-loggable in a future pass.
The AI Navigator is genuinely useful for testing navigation flows, but its reliability is entirely at the mercy of whatever vision model you point it at. It's opt-in and clearly labeled, but I'd want configurable fallback behavior before relying on it in CI.
Keep going
Want the parts I left out?
There's more behind every decision here than fits on a page. If something caught your attention, I'm happy to walk through it.