Case Study
AlchemizeCV
Resume tailoring grounded in real evidence: a Temporal-backed LLM pipeline from profile to rendered PDF to tracked application.
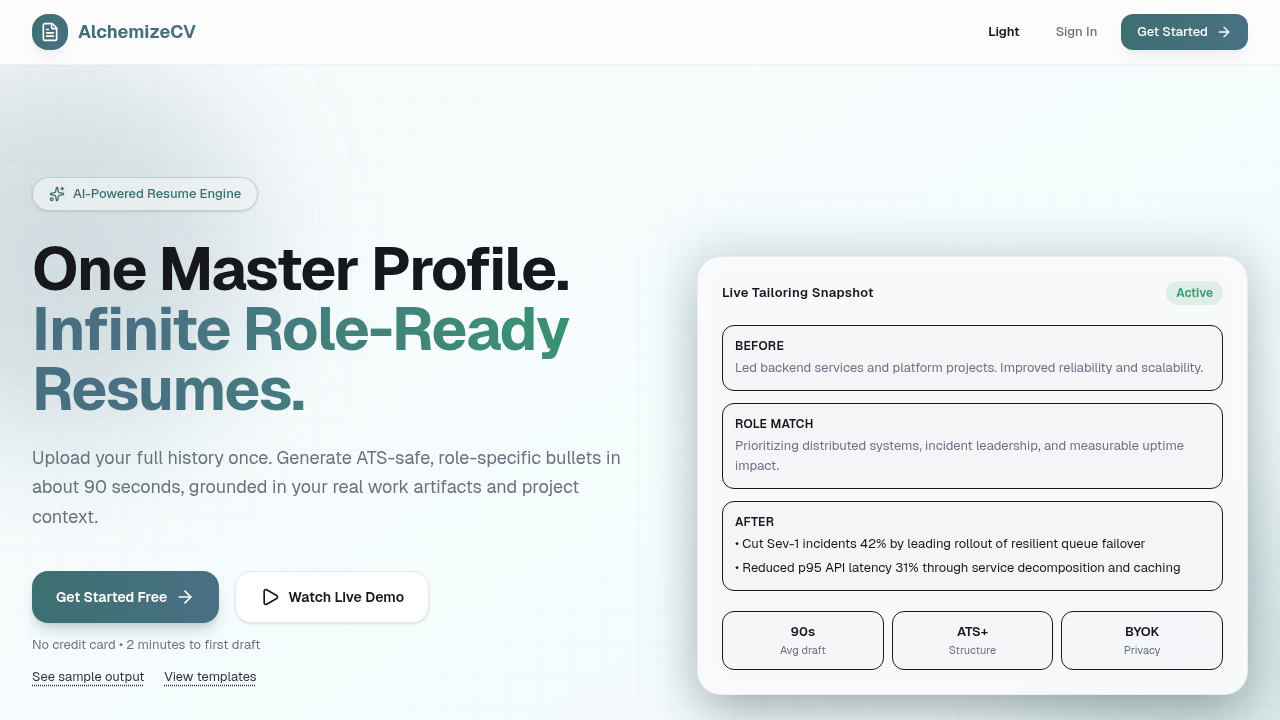
AlchemizeCV is a resume-tailoring and job-application platform I built to solve a problem I kept running into: job boards are hostile to automation, LLM-generated resumes tend to be generically polished and ATS-unfriendly, and the process of matching a real work history to a specific job posting requires more discipline than most tools apply. The result is a polyglot monorepo: Python 3.13 with FastAPI and Temporal for the backend, TypeScript/React 19/Vike for the frontend, Go for two separate runtimes, and a browser extension — all tied together with Dagger CI and Podman.
5
Temporal workflows
4
Language runtimes
4
LLM generation phases
What I want to walk through here is the unusual engineering underneath the surface, starting with the part I'm most interested in defending to another engineer.
An agent that uses bash instead of tool calls
The job automation subsystem needs an LLM to drive a browser, read pages, paginate through results, and hand back a JSON array of discovered job postings. The conventional approach is to expose browser actions as provider-native JSON tool schemas — a click tool, a navigate tool, a snapshot tool — and let the model invoke them. I didn't do that.
Instead, I built a custom agent runtime in Go (runtimes/job-automation/agent-harness) where the model communicates exclusively through two XML-style text tags: <bash>...</bash> to run shell commands and <final>...</final> to deliver its answer. No function calling. No tool schemas. The model gets a persistent bash session and a set of CLI binaries on its PATH.
The protocol parser in internal/protocol/parse.go classifies each model reply as KindExecute, KindFinal, or KindInvalid. A reply that contains both <bash> and <final> in the same turn is a protocol violation. A reply with markdown fences instead of the expected tags gets a targeted error nudge: "markdown code fences are not executed: wrap commands in <bash>...</bash>". After repeated violations the engine terminates the run with StoppedReasonProtocolViolations rather than spinning forever.
Every turn, the engine in engine.go sends the pending message, streams the reply, calls protocol.Parse, and dispatches. For KindExecute it runs the bash blocks sequentially through a shell.Session, collects exit codes and stdout, formats the results with structured markers ([STATE], [BLOCK N], [EXIT: N], [CWD: ...], [DURATION: ...]), and sends the formatted result back as the next user message. The format is defined once in protocol/format.go; the same constants appear in the guard that scans outgoing model text for reserved markers — if the model fabricates output that includes [STATE] or [BLOCK, the run stops with StoppedReasonFabricatedOutput. That's the integrity guarantee.
The bash-only design has a real tradeoff I thought about. Conventional tool calling gives you typed arguments, structured error codes, and easier retries on individual actions. What you lose is composability — once you commit to a tool schema, the model can only do what the schema describes. With bash, the agent can run rg, jq, patchright-cli batch 'fill @e3 query' 'click @e9', a heredoc checkpoint write, and a curl request all in a single <bash> block. It can install packages inside the container if it needs to. The instruction set is the shell. What I'd revisit: typed protocol violations are harder to surface cleanly through text, and the model sometimes needs several turns to figure out that a command isn't available before it finds the right binary on PATH.
Sessions are persistent and resumable. A ResumeState carries forward prior history, the previous run's final working directory, command counters, and the prior conversation so the model picks up exactly where it left off.
Browser automation on bot-hostile job boards
The shell binaries the agent can call include patchright-cli, a daemon-client browser automation CLI I wrote in Go and TypeScript/Bun (runtimes/job-automation/patchright-cli). It exists for one reason: job boards actively detect headless browsers, and the VPS has no display.
The solution is xvfb.ts, which allocates a free display number (starting at :99, scanning for an unused /tmp/.X{n}-lock), spawns Xvfb at 1920x1080x24, and sets process.env.DISPLAY. Then browser.ts launches Patchright with chromium.launchPersistentContext(profileDir, { channel: "chrome", headless: false, viewport: null }). The comment in the source makes the tradeoff explicit: do not set userAgent or extraHTTPHeaders because Patchright's stealth patches depend on the defaults being intact. Headful Chrome through a virtual framebuffer, against a persistent profile directory, is the setup that gets past bot detection on Greenhouse, Lever, Ashby, and similar boards.
The daemon listens on a Unix socket. Commands are serialized per-session — a single browser context runs one command at a time, which prevents snapshot-during-navigation races. The server in daemon/server.ts chains incoming requests onto a queue: Promise<void> and caches responses by request ID, so a retry with the same ID gets the cached result rather than reissuing a potentially mutating browser action.
The Go side of patchright-cli spawns the daemon (a Bun process) inside an ephemeral Podman container, waits for the ready line on stdout, then dispatches commands over the socket. The agent-harness executor derives a stable container name from the session directory so the same persistent container is reused across resumes of the same run — the browser state survives between turns.
The primary interaction surface for the agent is the accessibility snapshot: patchright-cli snapshot calls locator.ariaSnapshot({ mode: "ai" }), which produces a YAML tree with element refs like @e3, @e15. The snapshot pipeline in daemon/snapshot.ts post-processes this — hoisting link hrefs inline ([url=...]), stripping bare structural nodes, trimming depth on request. These filters exist to keep token counts reasonable; an unfiltered snapshot of a dense job board listing page is several thousand tokens.
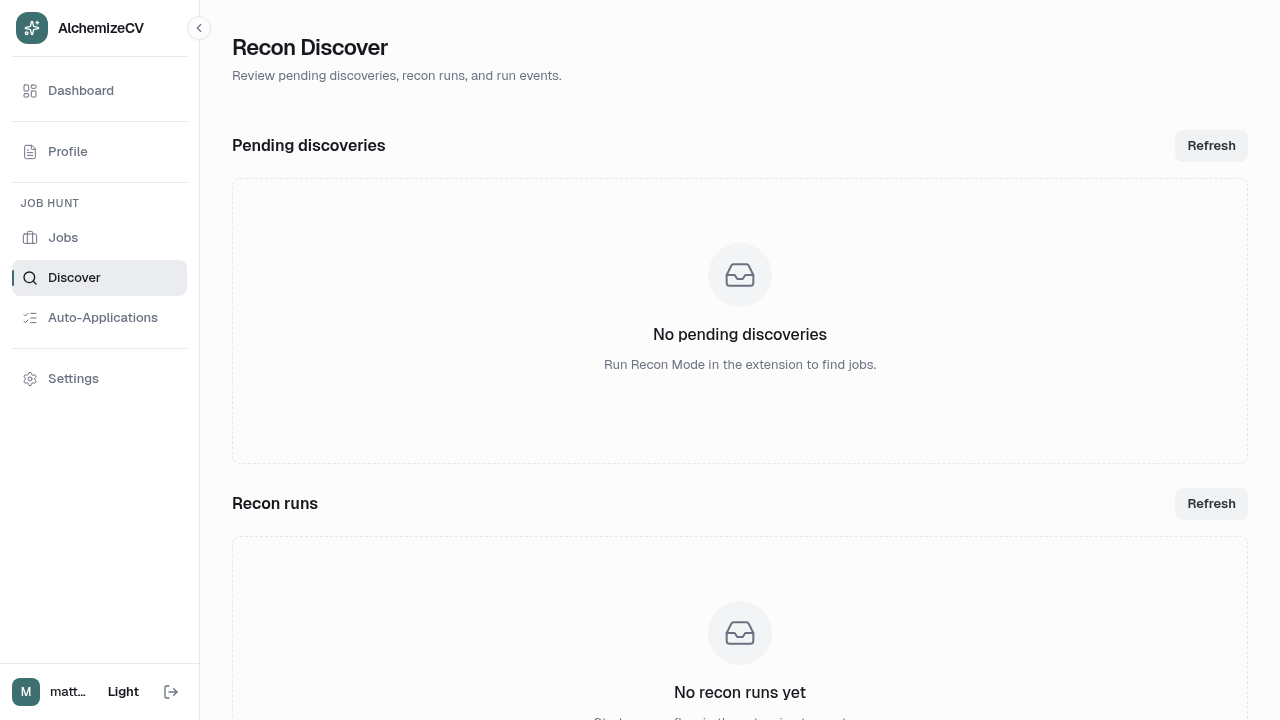
The scout system prompt in agent-harness/internal/prompts/scout.tmpl instructs the agent to use -i -u flags (interactive-only plus URL annotations) as its primary reading surface, take full snapshots only when needed, and checkpoint discovered postings to a file after every page before paginating. If the board shows a CAPTCHA or rate-limits the request, the agent stops and reports what it found rather than attempting any bypass.
The full path from the web app to a populated job board: user submits discovery criteria via POST /api/automation/sessions/job-discovery, the API starts a JobDiscoveryScoutWorkflow in Temporal, the workflow executes a single automation.run_job_discovery_scout activity with a 15-minute ceiling and no retries (a fresh browser session per attempt is expensive), the activity spawns agent-harness scout as a subprocess, the subprocess manages the full browser lifecycle, and its stdout — a JSON array of harvested postings — is parsed by parse_scout_output in scout_runner.py and upserted into the job pool.
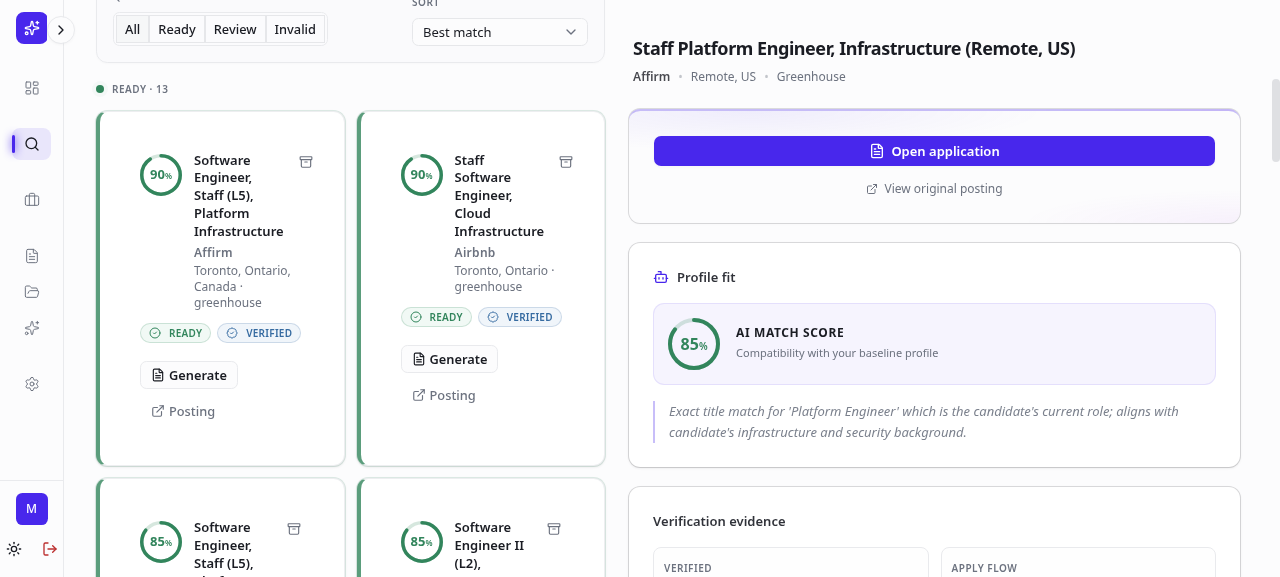
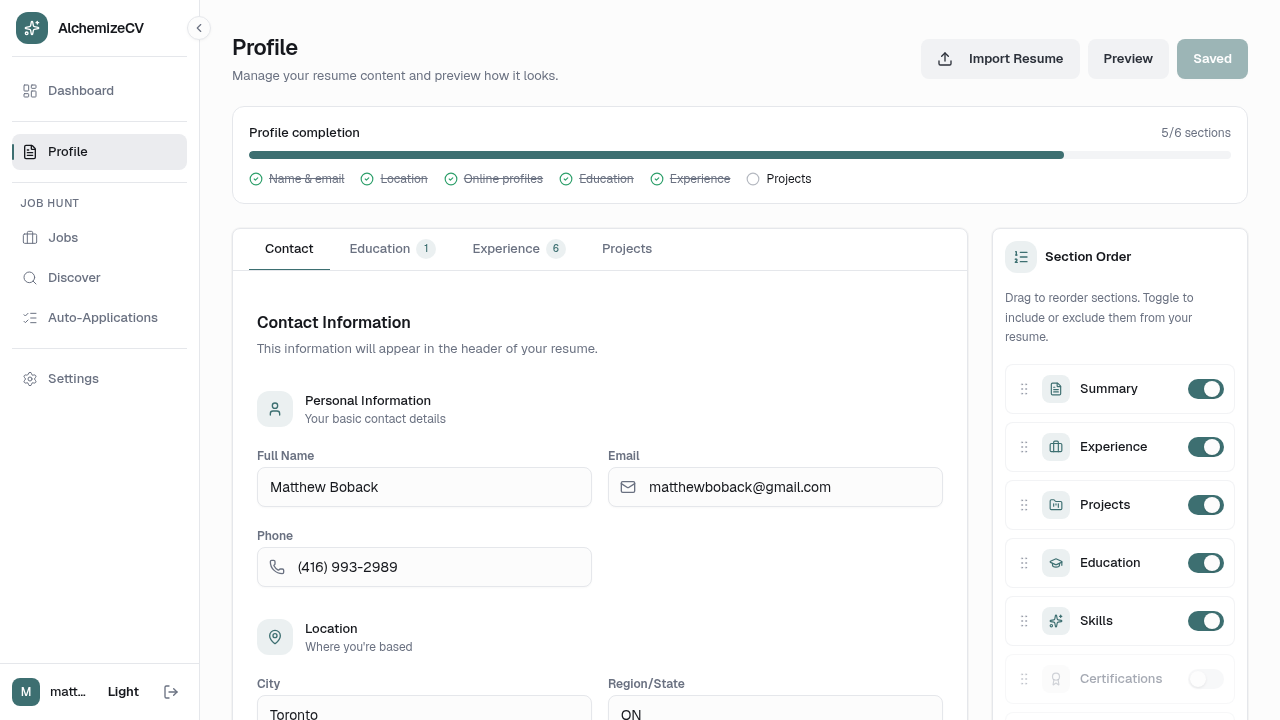
The resume editor with a live preview
The editor for a tailored resume is a split-pane view: the left side is a structured draft editor built in React, and the right side is a live preview rendered as HTML inside an <iframe> with sandbox="allow-same-origin".
The preview HTML is the same output that ends up in the PDF. PreviewDocumentFrame.tsx injects a data-print-sim stylesheet that sets padding and width to simulate 8.5x11 print layout, scales the iframe with CSS transforms to fit the available container width (using a ResizeObserver), and overlays page-break indicators as dashed lines when the content exceeds one page. The zoom controls allow free zoom from 40% to 200% or a "fit" mode that scales to fill the pane.
When the user selects a bullet point or section in the editor, a PreviewHighlightBox overlays a rounded highlight ring at the corresponding position inside the iframe. The position math accounts for iframe-to-container coordinate translation and iframe CSS scaling — the match uses findPreviewMatch against data- attributes in the HTML, computes the bounding rect, and applies the scale factor to map iframe-local coordinates back into container space. It's the kind of thing that works smoothly when it works and is deeply annoying to debug when it doesn't.
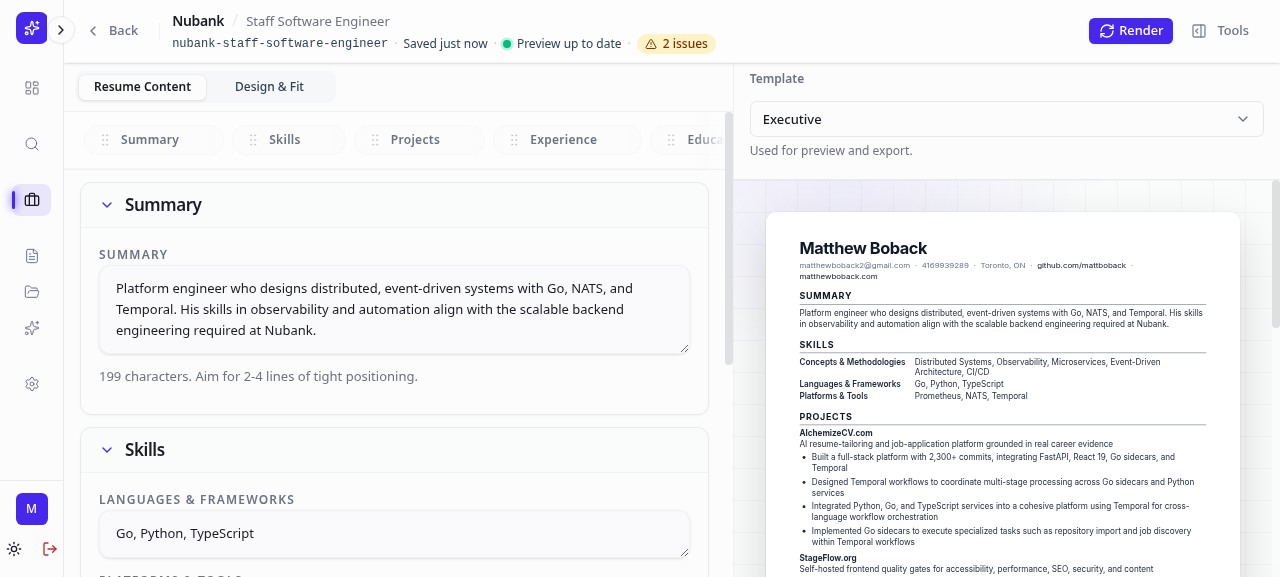
Generation state streams over a WebSocket. As each phase of the LLM pipeline completes, the UI reflects it in real time — the preview updates when the bundle is ready without requiring a full page reload.
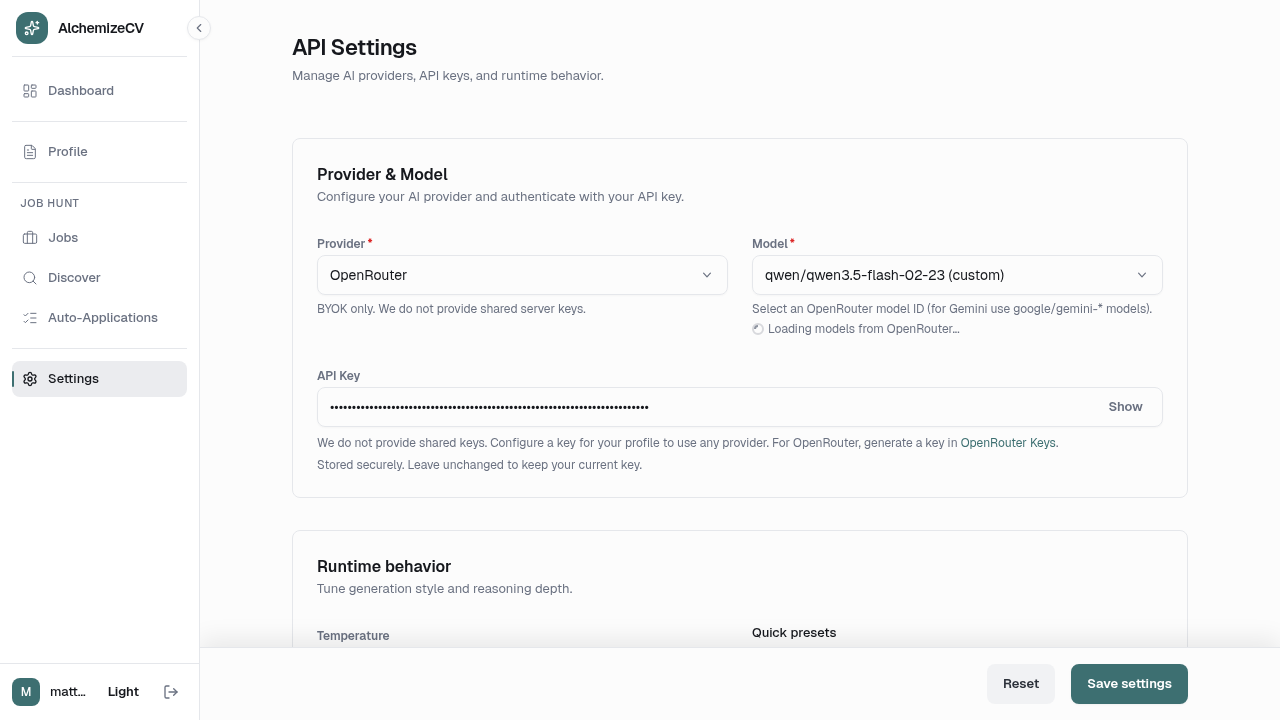
Temporal workflows, scoped tightly
The Temporal integration in runtimes/api runs five distinct workflows across three process roles: resume-generation-worker, render-worker, and automation-worker. Each workflow is narrow.
ResumeGenerationWorkflow chains four activity calls in sequence: create_projection (idempotent setup, 2-minute ceiling), run_raw_phase (LLM generates candidate bullets, 30-minute ceiling with 30-second heartbeat), run_pruner_phase (selects final bullets from candidates, 15 minutes), run_synthesis_phase (summary and skills section, 10 minutes), and run_bundling_phase (assembles the final bundle, 5 minutes). A fifth call, queue_render_handoff, fires off a RenderWorkflow and is wrapped in suppress(ActivityError) — a render queue failure adds a warning to the run record but doesn't fail generation. Cancellation is handled explicitly: both CancelledError and an ActivityError caused by cancellation call a cancel_run activity to write terminal state before re-raising.
The RenderWorkflow is two activities: create_projection and process_run. The renderer is a separate Python service that wraps Playwright and converts HTML to PDF; isolating it behind a workflow means render failures retry independently and don't block the generation worker process.
JobDiscoveryScoutWorkflow is as simple as a Temporal workflow can be — one activity, no retries, done. I made it a workflow at all because Temporal gives free observability and a clean failure record even for one-shot operations, and the activity boundary means the API HTTP handler returns immediately rather than waiting up to 15 minutes for a browser session.
Each activity follows the same pattern: open a sessionmaker() context, do the work, commit or roll back, return a payload. Activities that call the LLM pipeline use run_with_temporal_heartbeat to prevent the 30-second heartbeat timeout from firing during long model calls.
The generation pipeline
The four-phase LLM pipeline is where the actual resume tailoring happens, and it draws on a master profile the user maintains — experience, projects, education, imported GitHub repos. In the raw phase, the model generates RAW_CANDIDATE_COUNT (16) bullet point candidates per experience or project entry, each capped at 165 characters. The pruner phase selects the final set from those candidates; the floor scales with the target count so the pruner always has at least 3x headroom over small entries. The synthesis phase writes the summary and groups skills into three buckets: languages_frameworks, platforms_tools, and concepts_methodologies. The bundler phase assembles the full JSON bundle that feeds the HTML template and PDF renderer.
Each phase uses prompt caching at the provider level where available. The cache key structure in orchestration/cache_keys.py is designed so that re-running a phase with the same inputs hits the cache rather than issuing a fresh LLM call.
The rest of it
The repo-analysis service (runtimes/repo-analysis) is a Go binary with a tree-sitter parser that flattens a code repository into a token-budgeted, redacted digest. It was originally built to provide project context to the resume generation pipeline and is currently frozen — it does what it needs to do and there's no backlog to extend it.
The browser extension (runtimes/extension) is built with WXT and handles the human-in-the-loop application side: eventually it will let the agent drive form fills in the user's actual browser session, with a dry-run review before submission. That part is still in progress.
CI runs through a Dagger module in Go (ci/), which gates lint, tests, image builds, and smoke checks. Production deploys as Podman Quadlet systemd units behind a shared Caddy ingress, with the API running in different process roles selected by ALCHEMIZECV_PROCESS_ROLE — same container image, different behavior depending on what the orchestrator brings up.
Keep going
Want the parts I left out?
There's more behind every decision here than fits on a page. If something caught your attention, I'm happy to walk through it.